The Five Levels Between ChatGPT and Infrastructure

Most teams are stuck at Level 1 and think they’ve made it to Level 3.
That’s the single biggest pattern I see when people ask me to audit their AI setup. They have subscriptions. They have custom GPTs. And every Monday they’re still retyping the same instructions into a fresh chat window, wondering why the output feels generic.
The gap between using AI and building with AI is architectural, not incremental. You can’t prompt your way across it.
This is the framework. Five levels. For each one, I’ve mapped the definition, the signals that tell you you’re stuck there, the failure mode that forces the next move, and the trigger that tells you it’s time. Use it as a diagnostic. Find your level honestly, then move.
For the personal version of this journey with all the mistakes and walls I slammed into, see Every Wall Between Prompts and AI Teams. This article is the structural companion.

The five levels of AI maturity from ChatGPT to elite orchestration
Tools vs. systems: the fork everything hinges on
One distinction predicts everything else. If your AI usage doesn’t compound, you’re renting.
Tool usage is linear. Open window. Type prompt. Get output. Close window. Tomorrow, start from zero. Every session is a fresh re-teach.
System usage compounds. Agents have defined roles. Quality criteria are measurable. Workflows are reusable. What works gets captured and refined. Every project makes the next one better.
Level 1 and Level 2 are tool usage in different outfits. Levels 3 through 5 are systems, each more coordinated than the last. Knowing which side of the line you’re on matters more than knowing your exact level.
The mechanism behind compounding: feedback loop integrity
Here’s what actually separates Level 5 from everything below it. Not agent count. Not architectural complexity. Feedback loops.
Level 1 has no loop. You generate, you judge, you edit, and none of that signal gets back into the next session. Every error costs you human intervention. Every correction dies when the chat window closes.
Level 5 closes the loop. Every agent declares what it needs and what it delivers. Scores its own output. Flags its own edge cases. Leaves an audit trail. Validation creates signal. Signal enables correction. Correction accumulates.
That’s the engine. Everything downstream gets stronger because the system catches its own errors before they cost you anything. The levels aren’t stages of complexity. They’re stages of how much your system can learn from itself without you in the loop.
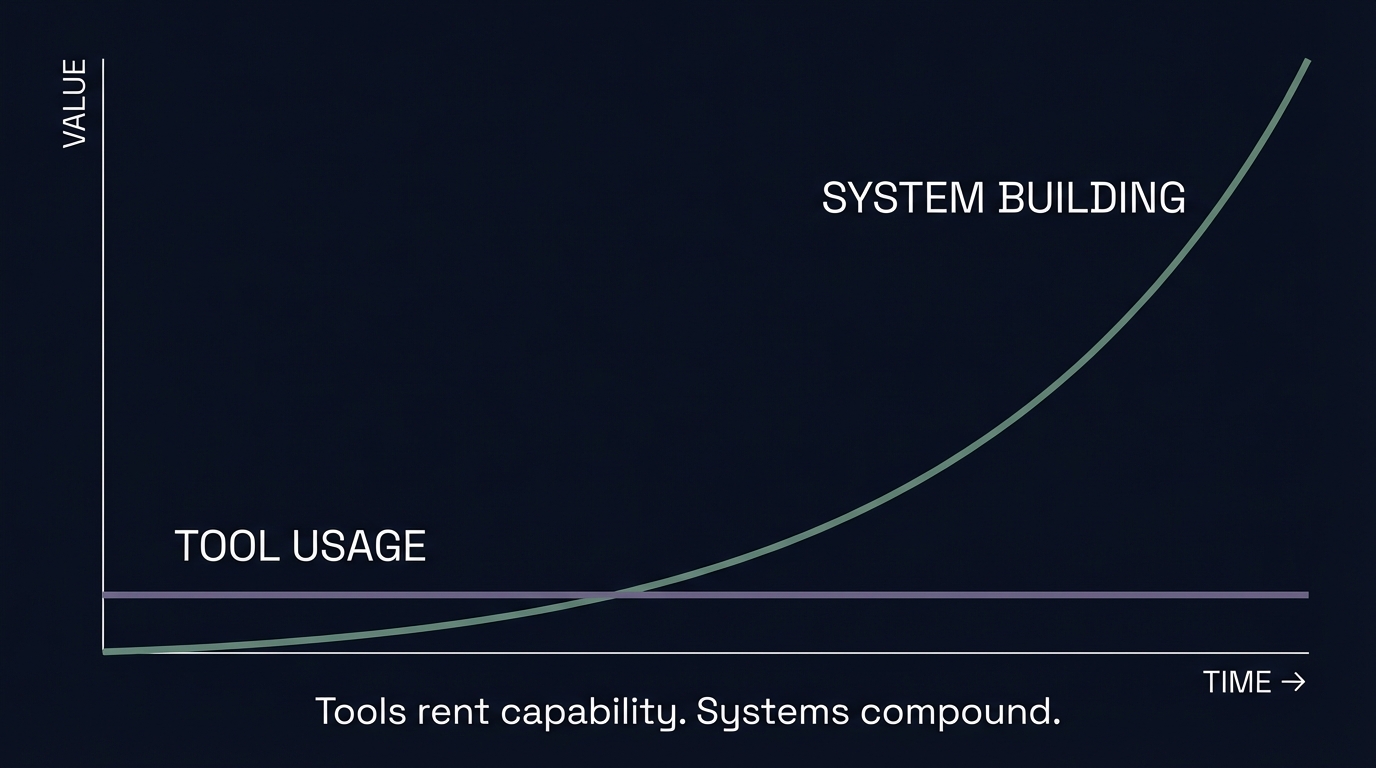
Tool usage stays linear. System building compounds.
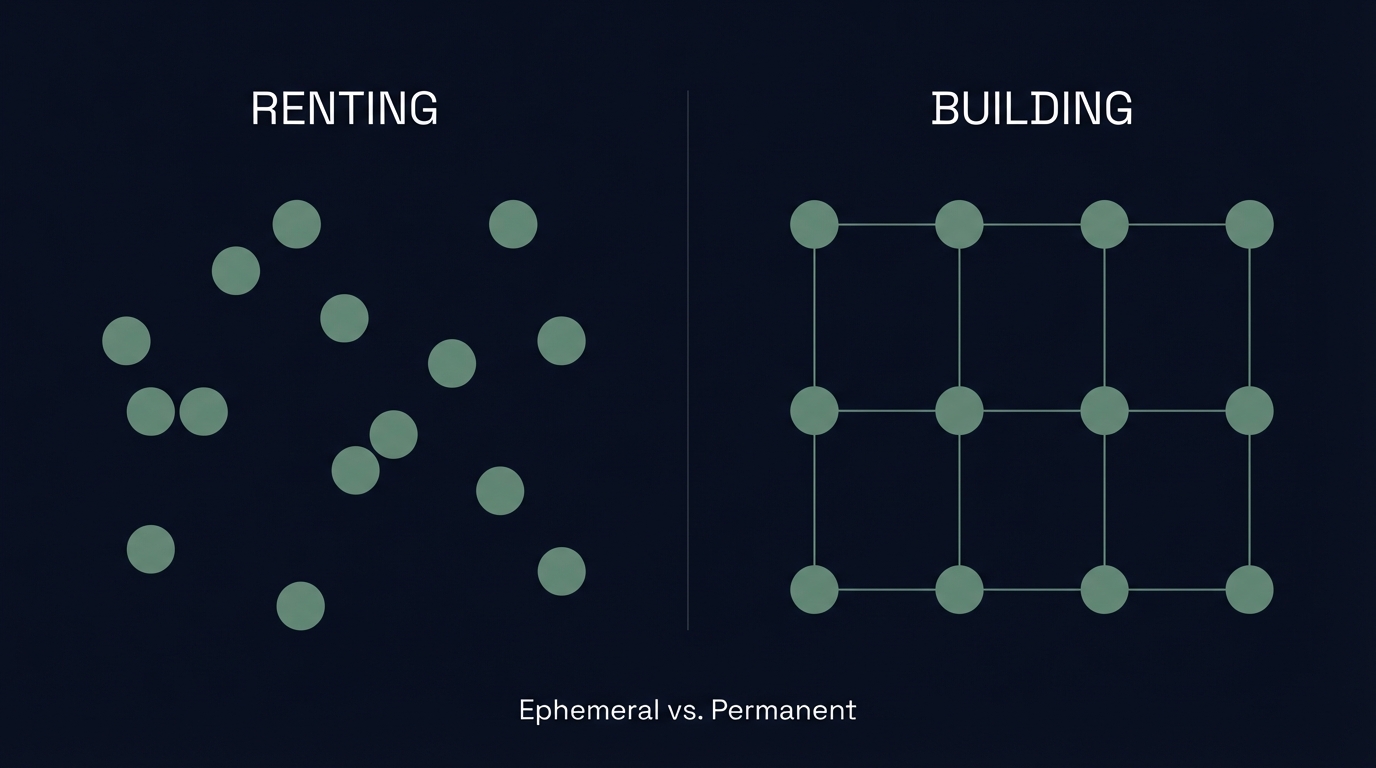
Ephemeral tool usage vs. permanent infrastructure.
Level 1: The ChatGPT window
Definition. One human, one chat window, one prompt at a time. No persistence, no role, no validation. Every session starts cold.
Diagnostic signals. You retype similar instructions every week. You edit outputs for 15 to 30 minutes to make them sound like you. Quality swings wildly between sessions. No version control for prompts. You can’t explain why yesterday’s output was good and today’s isn’t.
Failure mode. You’re re-teaching the AI from scratch every use. Paying a subscription for a tool you reintroduce yourself to every morning.
Upgrade trigger. The moment you notice you’ve pasted the same 300-word preamble four days in a row. Stop typing and start saving.

The template ceiling. 70 percent quality, no path above it.
Level 2: Templates and Custom GPTs
Definition. Pre-loaded instructions that give consistent outputs without retyping. Custom GPTs, saved system prompts, Notion-stored briefs.
Diagnostic signals. A named assistant for each common task. Outputs hit 70 percent quality reliably. Marketing generates ten LinkedIn posts in the time one used to take. Everything sounds on-brand. Nothing sounds remarkable.
Failure mode. You’ve industrialized mediocrity. Templates give consistency, not depth. The Blog Post Generator uses the same structure for a feature launch and a thought-leadership essay because it doesn’t know the difference. It has instructions. It doesn’t have expertise.
Upgrade trigger. When edge cases break the template and you realize you’re the quality filter. Every output needs you to rescue it. That’s not a template problem. That’s the ceiling.
What you need next isn’t better templates. It’s specialists.

Specialists as isolated islands. Close enough to see, too far to connect.
Level 3: Specialized agents
Definition. Instead of one Blog Post Generator, you build six specialists. An SEO Strategist. A Hook Architect. A Brand Voice Guardian. A CTA Specialist. A Technical Accuracy Reviewer. A Visual Storyteller. Each owns one domain and knows why its role matters.
Diagnostic signals. Output per agent jumps to 85 to 90 percent. The SEO Strategist analyzes search intent and structures for featured snippets, not just keywords. The Hook Architect applies actual psychological frameworks. For the first time, outputs feel like domain experts wrote them.
Failure mode. Every agent is excellent. In conflicting directions. The SEO Strategist writes a keyword-stuffed headline the Brand Voice Guardian hates. The Hook Architect writes a contrarian opener the CTA Specialist says misses the conversion goal. You become the human middleware, passing context between agents and losing 30 percent of it on every handoff. Level 3 fails silently in isolation. Each agent thinks it did its job.
Upgrade trigger. When you spend more time translating between agents than evaluating their output. The specialists work. The coordination doesn’t.
You don’t need more specialists. You need teams.

Coordination chaos. Clean intentions tangle without structure.
Level 4: Team-based agents
Definition. Multiple agents executing on the same project in parallel. A content workflow might involve twelve agents across a Research Team, a Creation Team, and an Optimization Team.
Diagnostic signals. Parallel execution is real. Throughput is up. Composite outputs hit 85 to 90 percent. And coordination has become its own full-time job.
Failure mode. Everyone finishes at different times. Handoff formats aren’t standardized. The Hook Architect optimized for one psychological driver, the Audience Psychologist identified a different one, and nothing resolves the conflict. Every project becomes a negotiation. When one agent stalls, the whole chain stalls. Teams without orchestration. Level 4 fails noisily in coordination. Unlike Level 3, you can see the collision in real time.
Upgrade trigger. The moment you realize the bottleneck is structural, not per-agent. You can’t fix this by making any one agent smarter. You need a spec every agent answers to.
What you’re missing isn’t better processes. It’s architecture.

Elite orchestration. Multiple agents in harmonic rhythm.
Level 5: Elite orchestration
Definition. Specialized agents organized into departments with clear mandates, documented workflows, and quality gates at every handoff. Engineering has six agents. Design has five. Marketing has six. Product has three. Testing has three. Project Management has two. Every agent answers to a production-grade spec (detailed below).
Diagnostic signals. The system compounds without you in the middle of every workflow. New projects benefit from refinements made on old ones. Quality increases with use rather than degrading with scale.
Failure mode. There’s a quiet one specific to Level 5. You think you got here because you have many agents, but you don’t have spec discipline. The system fragments into parallel Level 4s. Being at Level 5 isn’t about agent count. It’s about whether every agent in the system answers to the same spec contract.
Upgrade trigger. There’s no Level 6. The work at Level 5 is maintaining spec discipline as you scale. When you feel the urge to add another department, write its spec first.
The Five-Component Spec
This is what turns “collection of agents” into infrastructure. Every Level 5 agent is defined by the same five components. Skip any of them and you drop back to Level 4.
1. Input/output validation
Every agent declares what it needs and what it delivers. The SEO Content Strategist requires target keyword, search intent analysis, competitive landscape. It returns keyword clusters, structure recommendations, internal linking strategy. Missing inputs get flagged before work starts. No more “I didn’t have enough context” excuses.
2. Measurable quality criteria
Every agent is scored on weighted dimensions. The Blog Content Writer gets graded on narrative flow, technical accuracy, brand alignment, psychological resonance, SEO, and CTA effectiveness. A score below 92 percent triggers a self-critique loop. The agent explains why and proposes fixes.
3. Self-critique prompts
After generating output, every agent runs a self-evaluation. Does this hook use a recognized archetype? Does the CTA align with the primary motivation from audience research? Are there unexplained jargon terms? Quality control happens before human review, not after.
4. Edge case documentation
Every agent documents its known failure scenarios. The Twitter/X Specialist knows it struggles with deeply technical audiences because engineers prefer depth over snark. When the brief matches a documented edge case, the agent warns you: “Content targets CTOs. Contrarian hooks may backfire. Consider Question archetype instead.”
5. Real examples
Every agent ships with five to ten examples of excellent work. Articles with 10,000-plus views. Real campaign conversion data. Agents don’t work from theory. They pattern-match against proven success.
What this unlocks
Every handoff has a format. Every quality check has criteria. Every failure has documentation. The system gets better with use. That’s infrastructure. That’s compounding.
ROI across industries
The framework isn’t theoretical and it isn’t confined to content teams. Builders hitting Level 4 and Level 5 in very different domains report the same shape of result.
- Education. 60 to 70 percent time savings on lesson planning, assessment design, and curriculum development. Level 5 result: spec-based agent departments handling content ops with standardized handoffs. The numbers only land because the same spec governs every handoff.
- Gaming. Eight-person studios shipping on timelines that used to require 25 to 30 people. Level 5 result: full departmental orchestration replacing headcount, not supplementing it. Not possible below Level 5 because coordination overhead eats the gain.
- Fitness and health. 30 percent conversion lift on coaching funnels that moved from templates to orchestrated specialists. ~$85K per month revenue impact in one case. Level 4 result: the jump from Level 2 templates to coordinated specialist agents captured most of the gain. Level 5 adds the audit trail, not the conversion lift.
- Finance and compliance. Up to 80 percent reduction in compliance review cycle time. Back-office cycles collapse from days to hours. Level 5 result: spec-based orchestration with audit trails built into every handoff. Regulated industries need the documentation layer that only Level 5 produces.
Different industries, same mechanism. Systems that close their own loops beat tools that don’t.
Diagnostic: find your level
Honest answers only. Not where your LinkedIn bio says. Where you operate day-to-day.
| Level | You’re here if… | The trap | Your next move |
|---|---|---|---|
| 1 | You open fresh ChatGPT sessions and retype instructions every week | You think saved prompts in a Notion doc mean you have a “system.” Saved text is still tool usage. The AI can’t read your Notion. | Save one prompt today. Make it reusable this week. |
| 2 | You have Custom GPTs for every workflow and every output hits the same 70 percent quality ceiling | You think Custom GPTs are specialists. They’re templates with personality. No domain expertise, just better prompts. | Decompose your highest-volume task into 3-4 specialist roles. Build them separately. |
| 3 | Your specialists do excellent work individually but you’re the one shuttling context between them on every project | You think having multiple named agents means you have a team. You don’t. You have specialists with no shared language. | Standardize handoff format before adding another specialist. JSON schema, structured output, pick one and enforce it. |
| 4 | Your agents run in parallel and produce high-quality composite outputs, but coordination takes more time than review | You think parallel execution equals orchestration. It’s just chaos with more agents. | Write the five-component spec for one agent. Ship it, measure the difference, repeat. |
| 5 | The system compounds without you in the middle of every workflow. New projects benefit from old project learnings. | You think Level 5 is about agent count. It’s about the spec. You can be Level 5 with 6 agents. You can be Level 4 with 60. | Stay here. Maintain spec discipline as you scale. Every new department ships with its spec written first. |
If you’re stuck, here’s what to do
The table above gives you the one-line move. Here’s the longer version per level.
Stuck at Level 1. Save one prompt today. Turn it into a reusable template this week. That’s the whole move. You don’t need infrastructure yet. You need to stop retyping.
Stuck at Level 2. Pick your highest-volume content type. Decompose it into the three or four specialist roles it actually requires. Build those agents separately, even if coordination is manual for now. Specialization comes before orchestration.
Stuck at Level 3. Standardize your handoff format before you add another specialist. JSON schema, structured output, pick one and enforce it. Most Level 3 teams think they need better agents. They need better interfaces between agents.
Stuck at Level 4. Write the five-component spec for one agent. Just one. Input/output validation, quality criteria, self-critique, edge cases, real examples. Ship it, measure the difference, then do the next one. Level 5 gets built one spec at a time, not in a big-bang redesign.
The real question
Most people use AI like a hammer. One tool, one function, one point of impact. Swing it when you need it. Put it down when you’re done. No memory, no collaboration, no compounding.
Elite systems use AI like an orchestra. Specialized agents, each with clear expertise, coordinated by a score that says when each section enters and how they harmonize.
The output isn’t louder. It’s qualitatively different.
The question isn’t whether agentic AI works. It’s whether you’re willing to build systems that close their own loops.
This framework comes from building production agentic systems at scale. For the personal narrative of how I got here, including what I got wrong at each level, read Every Wall Between Prompts and AI Teams.
Subscribe to the Newsletter | Follow on Twitter/X | Connect on LinkedIn
Continue Reading:
- Every Wall Between Prompts and AI Teams — the personal-journey companion to this framework
- Foundations of a PM — core product management principles
- Grading My 2025 Crypto, AI, and Gaming Calls — where AI is headed